Abstract
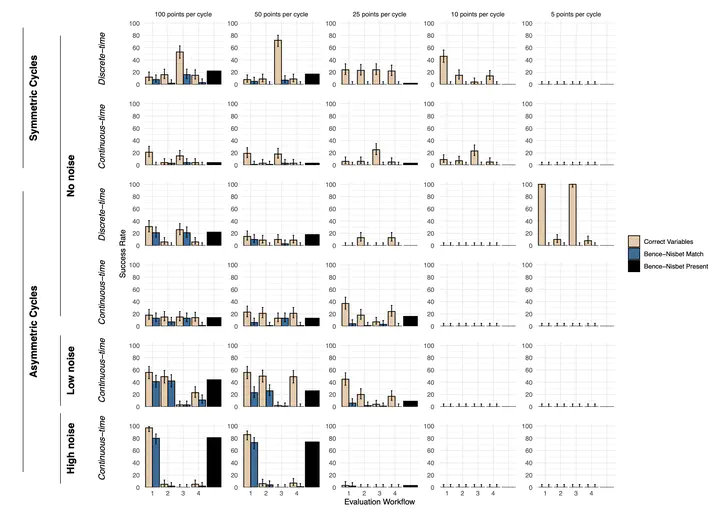
Applications of machine learning in ecology are rapidly expanding. Symbolic regression is gaining particular attention for its success in reverse-engineering human-readable explanatory population models, including the logistic growth and Lotka-Volterra equations, from simulated and laboratory-based population time series. However, field-based populations often lack the characteristics of the idealized time series used in prior assessments. We evaluated the utility of symbolic regression for such time series by quantifying its success for synthetic data varying in sampling density, population cycle asymmetry, process noise, and the erroneous consideration of spurious variables. We further compared two data preprocessing options for estimating population growth rates, and four evaluation workflows for selecting equations. Results indicate that a trade-off between sampling density and process noise primarily drives equation and variable recovery. Symbolic regression failed to recover the underlying equation at sampling densities below 10 points per cycle; however, at higher sampling densities, process noise did increase equation recovery rates. Importantly, although the true model was frequently recovered at sampling densities of 25 or more points per cycle, it was not consistently selected by the evaluation workflows. This discrepancy highlights a need for more robust post-algorithm selection criteria to identify the focal equation among competing candidates.